数据备份和恢复在分布式文件系统中对技术人员来说是一项难题,这主要是因为它需要在众多节点之间进行数据复制,还要应对故障,既复杂又至关重要。
一数据备份基础
数据需分散存储于众多节点之中。这相当于将资料分散保存在多个“小仓库”中。这样做既确保了数据的即时可用性,又赋予系统一定的容错能力。众多大型企业的数据中心倾向于在多个区域设立节点以存储数据。例如,某家公司在北京、上海及广州均设有节点以保存数据副本。若某一节点出现故障,其他城市的节点可立即接替其工作。此方法显著减少了单个节点故障的可能性,确保了数据在任何情况下都能被顺畅访问。
数据统一性同样至关重要。以电商平台为例,存储商品信息时,各节点数据必须一致,否则会导致混乱。商品价格、库存等关键信息也必须保持一致,这需要我们进行复杂的数据同步工作。
二数据复制策略
在分布式文件系统里,数据复制是普遍采用的策略。在网络云存储领域,为了确保用户能够随时访问数据,数据会被持续地复制至多个数据中心。通过这种方式,即便某个数据中心出现故障,服务也不会受到影响。
def create_file(self, file_name):
self.files[file_name] = File(file_name)
def copy_file(self, src_file_name, dst_file_name):
src_file = self.files[src_file_name]
dst_file = self.files[dst_file_name]
dst_file.copy_from(src_file)分散数据至多个节点时,需慎重选择分配方案。需留意避免部分节点承受过重负担,同时确保其他节点不被浪费。以一家小型分布式存储企业为例,节点A存储了10TB数据,而节点B仅有2TB,这就要求我们精心规划,确保资源公平分配,进而保障数据安全与高效存储。
def copy_from(self, src_file):
self.data = src_file.data三故障恢复的策略
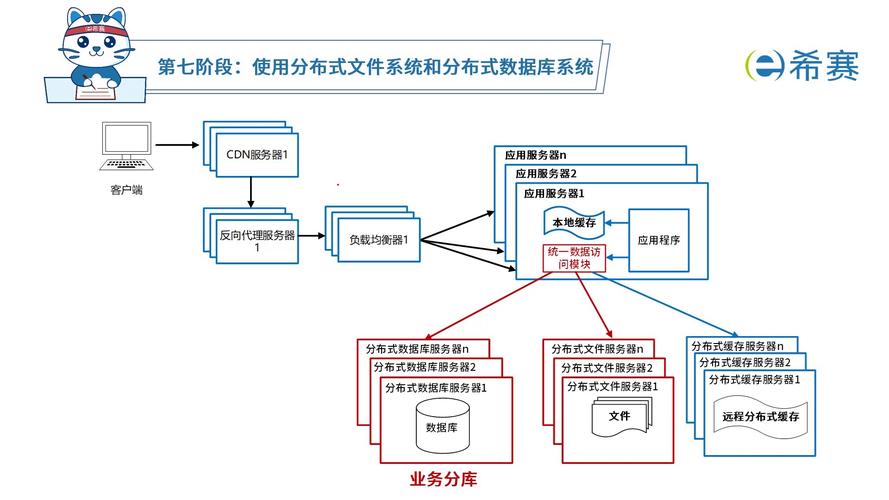
故障恢复计划至关重要。若某个节点发生故障,它便成为了解决问题的关键。以某知名互联网企业的数据存储系统为例,当节点Y出现故障,依据既定的恢复措施,其他运行正常的节点将负责重新分配和调整数据和资源。
该策略运用了特定的数学公式,目的是对故障恢复的概率、效果和表现进行评估。这就像解决数学问题一样,借助这个公式,我们能够事先预测系统的稳定性。有了这些数据,技术人员可以提前制定应对措施,保障数据安全,防止信息丢失。
def get_file_data_from_node(self, node, file_name):
# 假设从节点中获取文件数据的方法
pass四常见备份恢复策略
通常的做法有定期的数据存档以及差异存档等。在职场中,对办公资料进行定期存档,能确保每日的工作成果不会遗失。假如员工昨日已保存了关键文件,而今日服务器出现故障,那么这些定期存档便能派上用场,协助找回那份文件。
差异备份只记录数据变化的部分,这样做能有效减少存储空间的需求。就好比监控录像,大部分时间画面都相同,我们只需保存那些出现变化的片段。
五数据一致性维护
在数据备份和恢复过程中,保持数据的一致性是个难题。比如,在图像存储系统中,不同节点对同一图像的存储格式或编码可能存在差异。这时,我们必须检查数据的一致性。
在众多节点里,我们可以挑选一个作为检验的参考点。比如,我们会挑选那个既牢靠又信息更新迅速的节点。接着,我们将把其他节点的数据与这个参考点进行比对和修正。这样做的目的是确保无论选用哪个节点的数据,其准确性都能保持稳定。
六应对其他问题
在数据备份和恢复的操作中,偶尔会遇到数据转移的难题。比如,当公司打算将旧的硬盘存储系统更新为新的闪存存储系统时,就需要进行数据转移。在此过程中,我们必须确保数据既不会丢失,也不会受到损坏。
另外,在不少步骤里,数据压缩与加密的处理方式并不一致。比如在金融领域,由于对安全性的高标准,不同环节采用的压缩加密手段各有差异,这就需要我们建立一套统一的标准。若不这么做,可能会遇到数据读取上的难题,还可能降低数据的安全防护水平。
在分布式文件系统的数据备份与恢复这一专业领域,我们期待大家能展开深入交流。你认为,哪些技术有望在未来获得更广泛的应用空间?欢迎点赞并分享你的见解,也欢迎在评论区留下你的观点。
发表回复