若要实现服务器对请求的高效处理?那么负载均衡算法至关重要!然而,各种算法各具特色,究竟如何挑选?接下来,我将为您详细介绍五种常见的负载均衡算法。
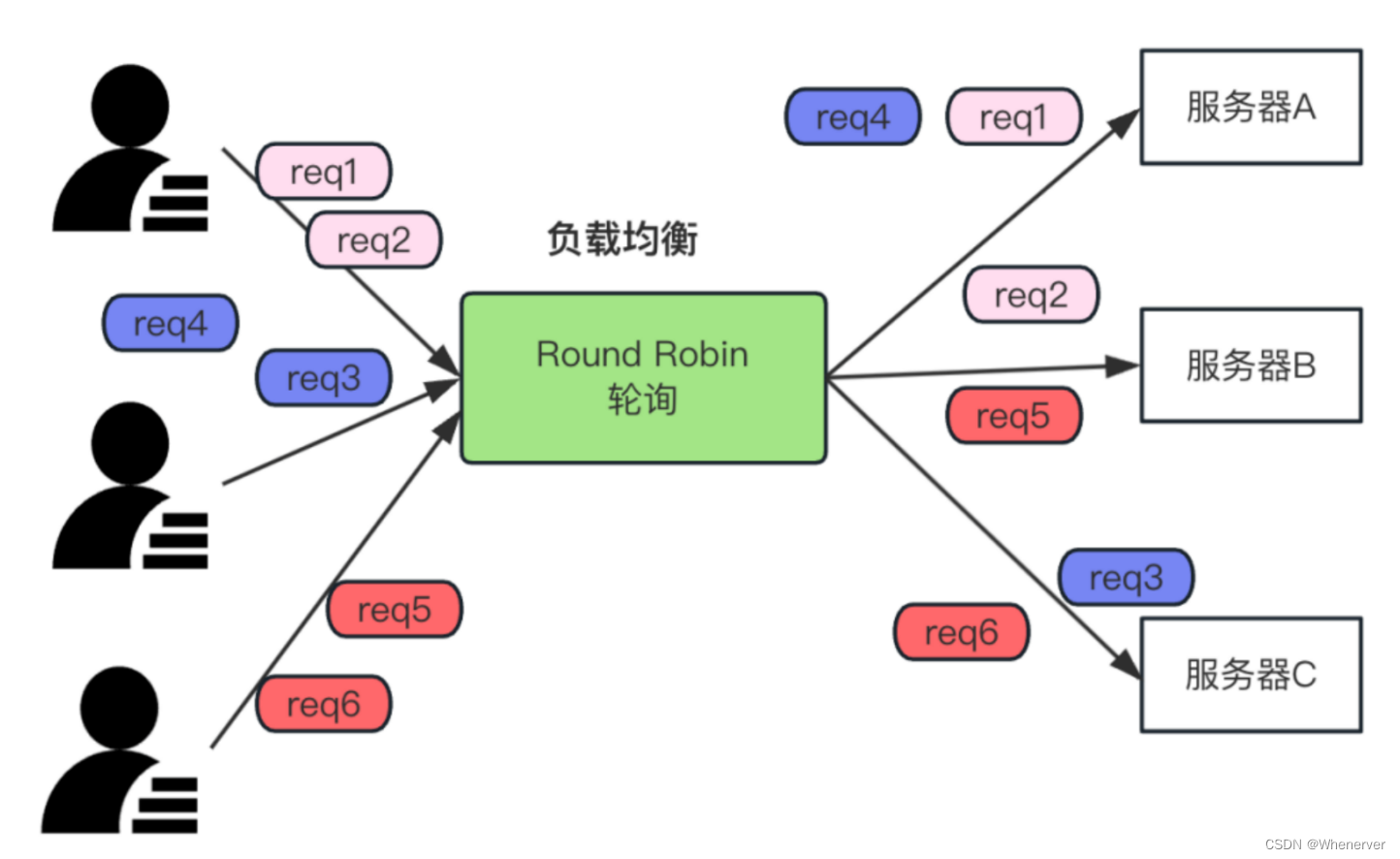
轮询算法介绍
轮询算法操作简便。设有A、B、C三台服务器,当客户端发起请求,会依次按A到B、B到C、C到A的顺序进行分配。其伪代码涉及一个服务器列表和当前服务器的指针。Nginx系统默认采用此算法。在没有特别需求的情况下,使用它既方便又易于操作。
轮询算法使用场景
# 服务器列表
servers = ["ServerA", "ServerB", "ServerC"]
# 当前服务器
current_server = 0
# 轮询算法
if(req):
# 选择当前服务器来处理请求
process_request(servers[current_server])
# 将当前服务器移到服务器列表的末尾
if current_server == length(servers):
current_server = 0
else:
# 指针+1
current_server += 1
轮询算法在很多场景下都挺适用。像那些小型的网站,访问量不大,服务器性能也相仿,那它就挺合适的。若是一家小公司的内部管理平台,用户数不多,通过轮询算法将请求平均分配到各个服务器,便能确保系统稳定运行。而且,这种方法成本低,配置也简单。
servers = ["Server1", "Server2", "Server3"] # 服务器列表
current_index = 0 # 当前服务器的索引
def get_next_server(self):
if not self.servers:
return None
# 获取当前服务器
current_server = self.servers[self.current_index]
# 更新索引,移到下一个服务器
self.current_index = (self.current_index + 1) % len(self.servers)
return current_server
# 创建一个包含服务器的列表
servers_list = ["ServerA", "ServerB", "ServerC"]
# 模拟请求的处理过程
if(req): # 假设有5个请
next_server = get_next_server()
if next_server is not None:
process_request(next_server)
else:
print("No available servers.")
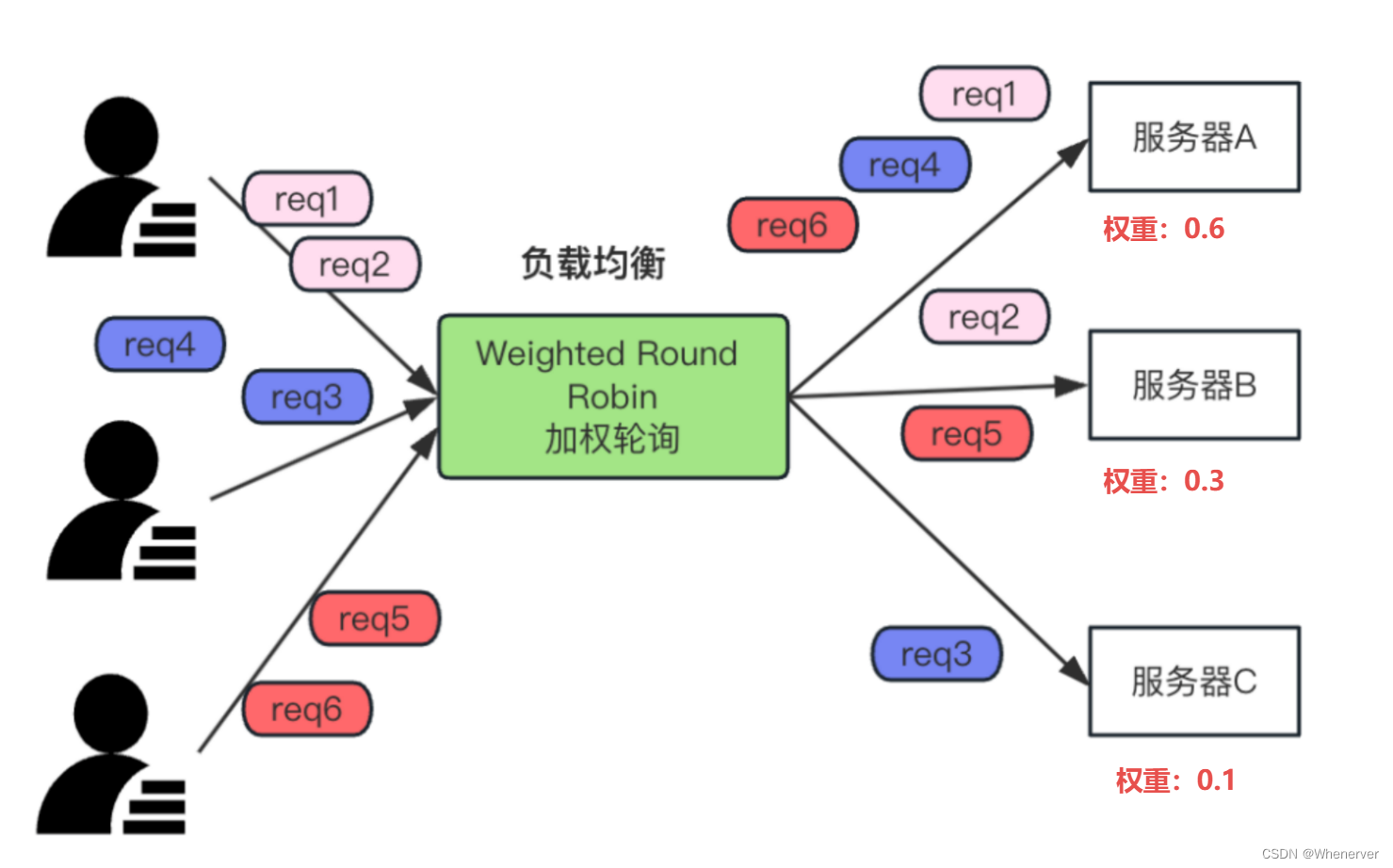
加权轮询算法原理
servers = ["Server1", "Server2", "Server3"] # 服务器列表
current_index = 0 # 当前服务器的索引
def get_next_server(self):
if not self.servers:
return None
# 获取当前服务器
current_server = self.servers[self.current_index]
# 更新索引,移到下一个服务器
self.current_index = (self.current_index + 1) % len(self.servers)
return current_server
# 创建一个包含服务器的列表
servers_list = ["ServerA", "ServerB", "ServerC"]
# 模拟请求的处理过程
if(req): # 假设有5个请
next_server = get_next_server()
if next_server is not None:
process_request(next_server)
else:
print("No available servers.")
加权轮询算法是轮询算法的升级版本。在处理负载请求时,它会考虑服务器的权重。权重越高,分配到的请求就越多。其实现方式与轮询算法相似,但会根据权重在列表中分配不同比例的服务器。同时,它也会设定服务器列表和当前服务器指针。例如,性能较好的服务器会被赋予更高的权重。
加权轮询算法优势
加权轮询算法更高效地分配服务器资源。以三台服务器为例,若A的性能远超B和C,则赋予A更高的权重。这样A可以处理更多请求,充分发挥其性能。相较于普通轮询算法,这种方法更为合理,能提高系统整体处理速度,防止优质服务器资源闲置,以及避免性能较差的服务器承受过重负担。
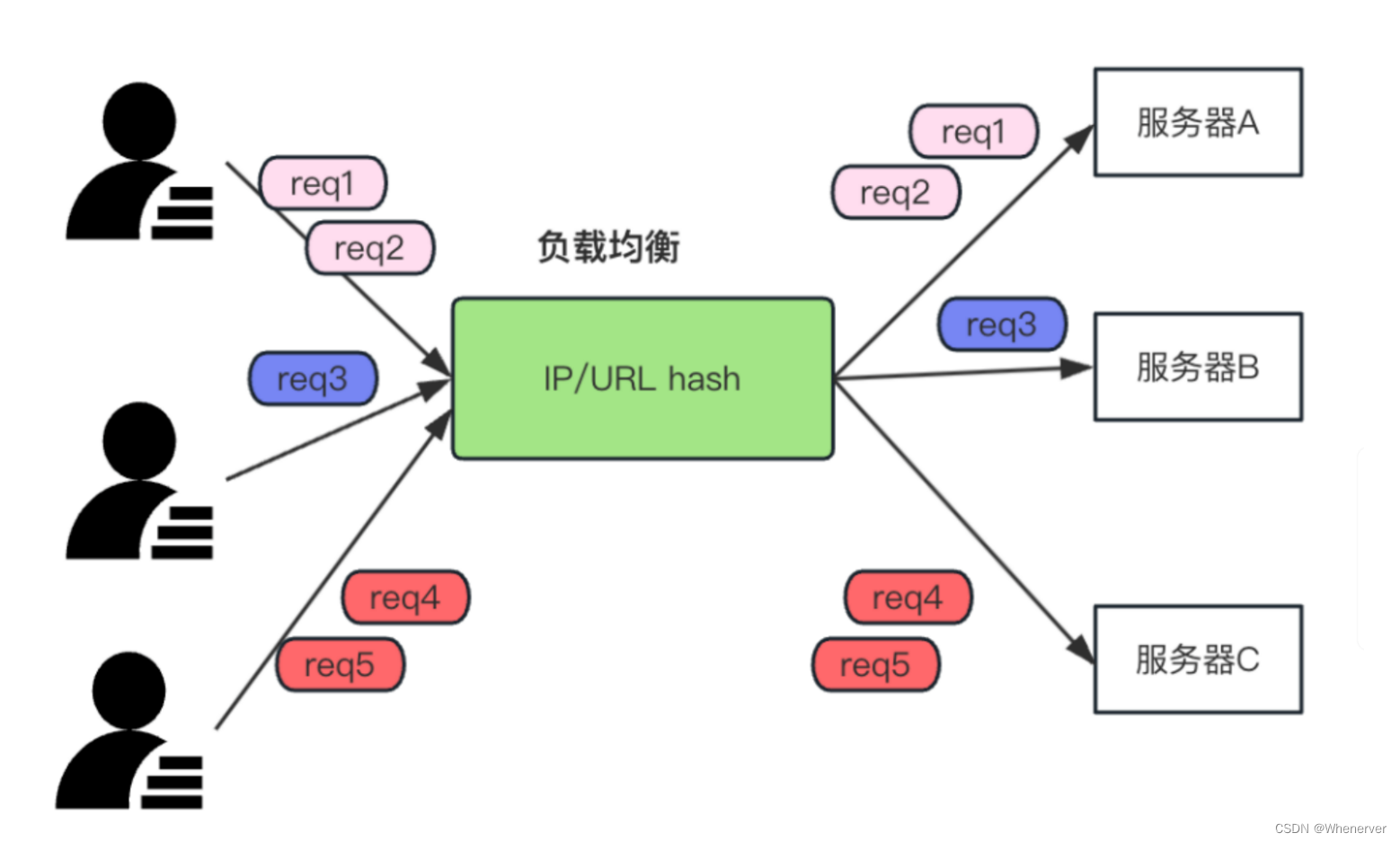
IP/URL散列算法机制
根据客户端的IP或URL,请求会被分配到相应的服务器。若IP或URL相同,它们会被导向同一服务器。以一个大型电商网站为例,设有A、B、C三台服务器,来自相同IP的请求都会被送至同一台服务器。这样做可以确保用户操作时的数据保持一致,防止数据出现混乱。
# 服务器列表
servers = ["ServerA", "ServerA", "ServerA", "ServerB","ServerB", "ServerC"]
# 当前服务器
current_server = 0
# 轮询算法
if(req):
# 选择当前服务器来处理请求
process_request(servers[current_server])
# 将当前服务器移到服务器列表的末尾
if current_server == length(servers):
current_server = 0
else:
# 指针+1
current_server += 1
IP/URL散列算法问题
然而,IP/URL散列算法并非完美。若某台服务器性能极为出色,比如服务器A,那么所有相同IP或URL的请求都会集中到它那里,而服务器B和C则始终处于闲置状态。这就像有三个工人,所有的活都分配给了那个最能干的,其余两个却无所事事,导致资源未能得到有效利用。
轮询及加权轮询算法缺点
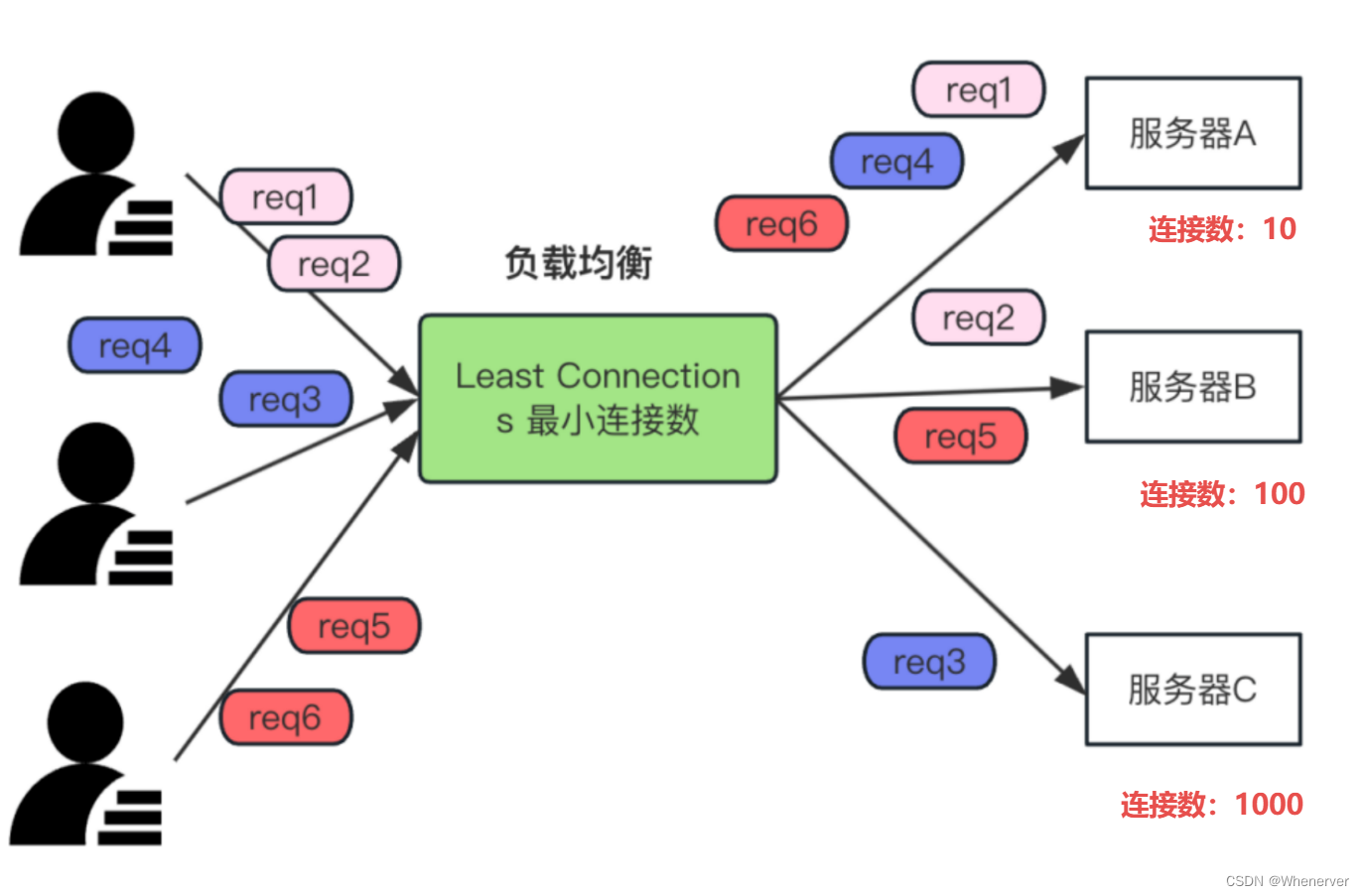
轮询和加权轮询算法存在一个共同缺陷,即无法应对服务器的动态变化。若服务器突然出现故障,算法无法自动将其排除。以服务器B为例,若其突然宕机,请求仍会发送至B,这可能导致请求失败,进而影响系统的稳定性。
# 创建一个包含服务器及其连接数的字典
servers = {"Server A": 5, "Server B": 3, "Server C": 4}
def get_server_with_least_connections():
# 找到当前连接数最少的服务器
min_connections = min(servers.values())
# 找到具有最小连接数的服务器
for server, connections in servers.items():
if connections == min_connections:
return server
# 选择连接数最少的服务器
def assign_request(self):
# 获取具有最小连接数的服务器
server = get_server_with_least_connections()
if server is not None:
# 模拟分配请求给服务器,增加连接数
self.servers[server] += 1
return server
else:
return "No available servers."
# 模拟请求的处理过程
if req: # 假设有请求
assigned_server = load_balancer.assign_request()
其他应对办法
为了应对这一问题,我们可增设一个监控体系,对服务器运行状况进行实时跟踪。一旦发现服务器出现故障,可手动或自动更新服务器清单,移除故障服务器。此外,还可以研发更先进的算法,使其能自动检测服务器状态并进行相应调整。
总结综合情况
这些负载均衡方法并不复杂。在生产环境中,需根据具体业务需求挑选恰当的算法。若访问量稳定且服务器性能相近,轮询法即可;若服务器性能悬殊,则应采用加权轮询。而对于追求数据一致性的业务,IP/URL散列算法更为适宜。
结合实际运用
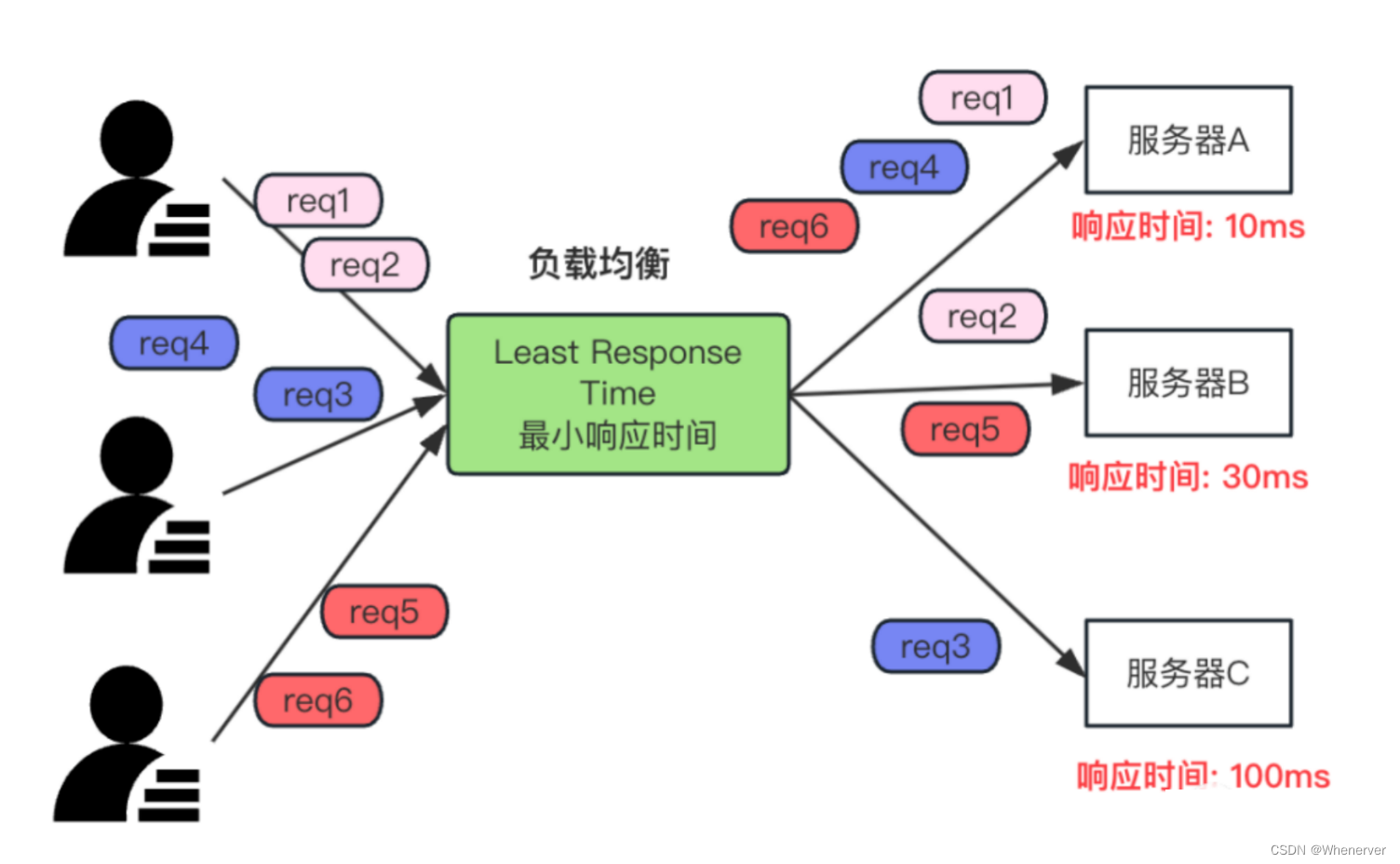
在生产实践中,我们通常不亲自编写算法,而是采用nginx、lvs、haproxy等现成的框架。然而,掌握这些算法的基本原理,有助于我们更深入地理解并优化这些框架的配置,从而使系统运行更加高效。
在实际工作中,您是否运用过某种负载均衡技术?在使用过程中,您是否遇到了困难?若您觉得这篇文章对您有所帮助,请记得点赞并转发!
发表回复